Clever Title About Memory
A few of the following posts will require a basic understanding of the memory layout used by the microcontrollers we’re building FieldKit on top of. For many software developers this will be old news, but I wanted to take the time to make sure we’re on the same… page.
Basically, memory is laid out in specific regions from a functional/hardware perspective and then further subdivided by software. So, let’s start with some common diagrams:
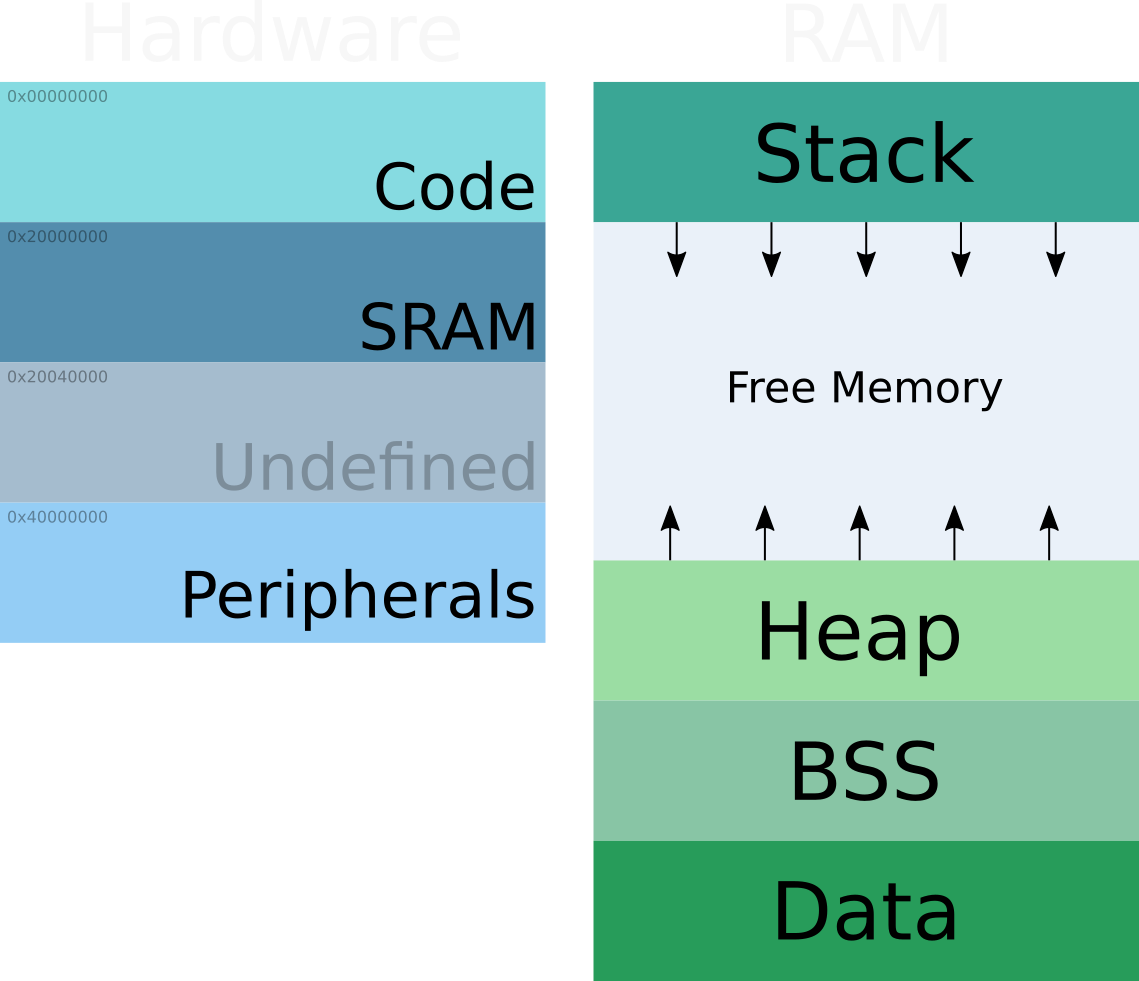
Hardware Memory Layout
Many of us have seen this, I’ll just give a quick summary:
- Code: This is where program code and static data is stored. This memory is changed very infrequently. Understanding that data can also live here is important. The data that lives here cannot be changed, though without jumping through significant hoops. One common piece of data is the default vector table that’s used by the hardware to kick off the execution of software.
- SRAM: Ah glorious RAM. This is where the state of our software is stored during its execution. It’s a treasured and valuable resource and the one most significantly imposed upon by software. By the way, you can run instructions from SRAM, at least on our architecture.
- Peripherals: The physical hardware and how the software interacts with it is mapped to memory in this region. It’s how the hardware makes itself available and is, hopefully, abstracted behind an intuitive software layer. We’ll be talking the least about this region.
Now, summary imposes its own structure on memory, too. When our firmware first runs, part of its initial tasks is to setup and initialize various parts of RAM. Establishing a layout like this:
RAM Layout
This is where things are getting interesting!
- Data: Our software contains variables and data that begin with a known value and will be modified over time. This is where that data lives. One of the first tasks of the software is to copy this data from the read-only Code memory to SRAM. Not only that, but to a place in SRAM where the executable expects that data to be! This caveat will be important later.
- BSS: Some variables don’t have an interesting initial value and just begin with 0. Rather than storing a huge block of 0’s we save space by just remembering how big this region needs to be and initializing that are to 0. The name BSS is a throwback to the early days of computing.
- Heap: This is where memory dynamically allocated by the software comes from. It is the first region that changes size and typically starts with a size of 0 at the start of execution. Notice that this region grows upward over time and can also shrink. Calls to malloc/free pull memory from here, as well as the plain calls to C++’s new/delete.
- Stack: This region stores local variables, function parameters, and return addresses. It grows downward, towards the heap. It also plays a big role in handling interrupts in that certain state is pushed onto the stack prior to calling those routines. It will come up later when we discuss multi-tasking.
Now that we’re… aligned, we can move onto more interesting subjects 🙂